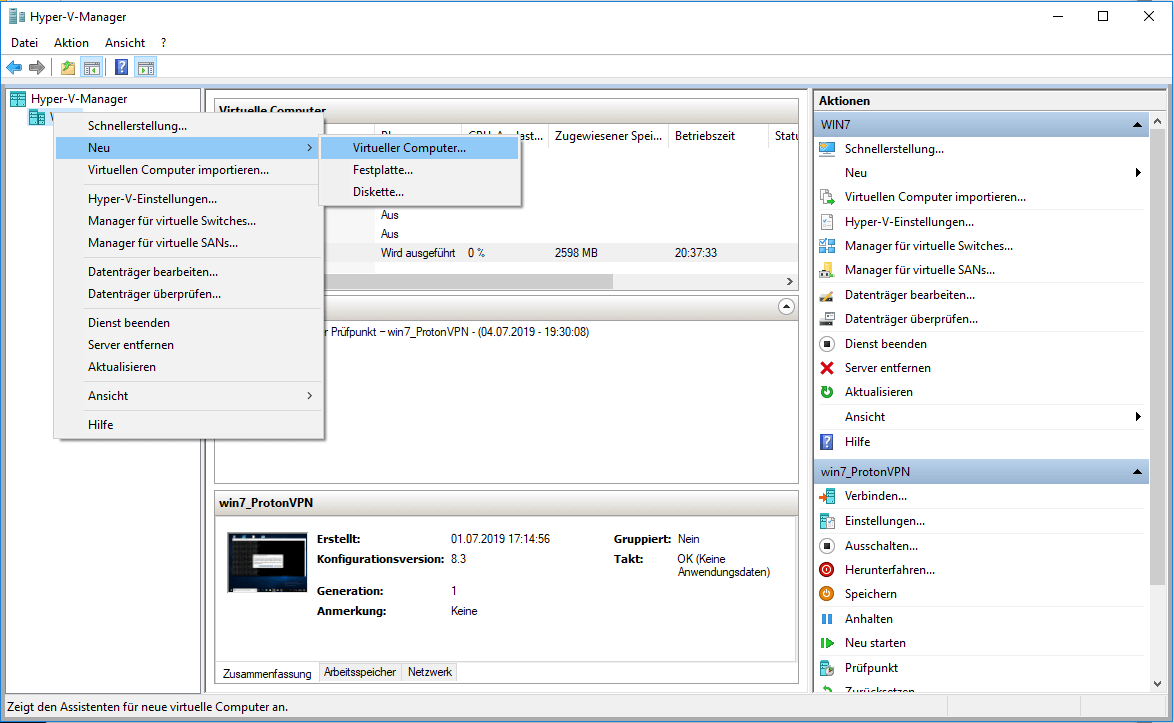
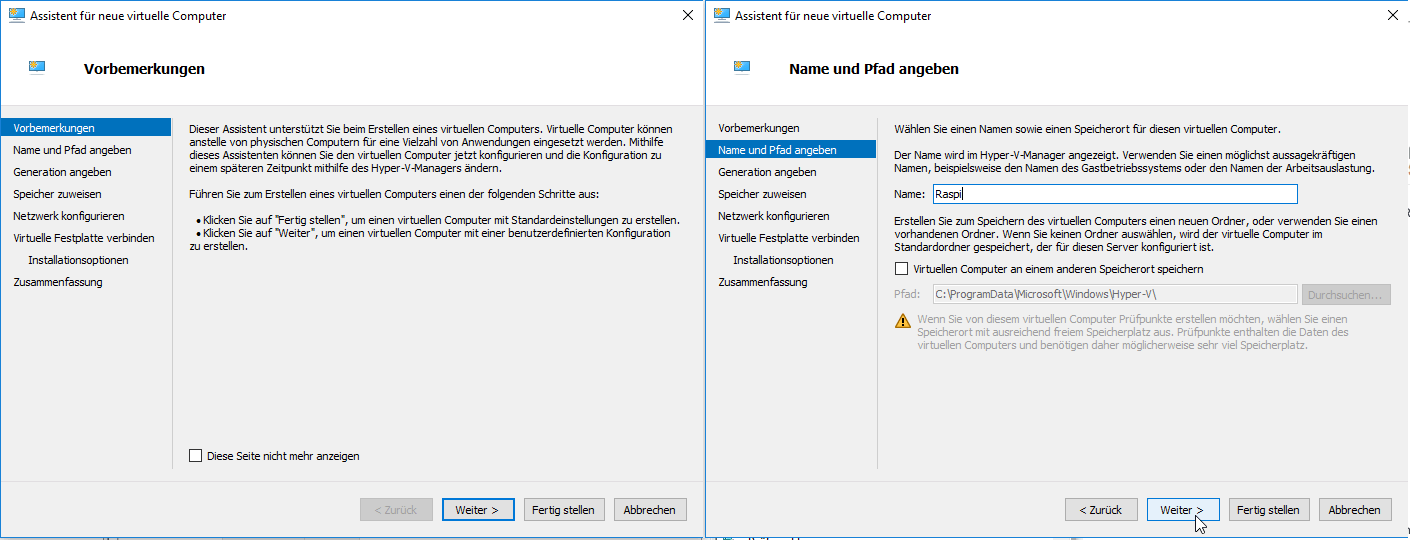
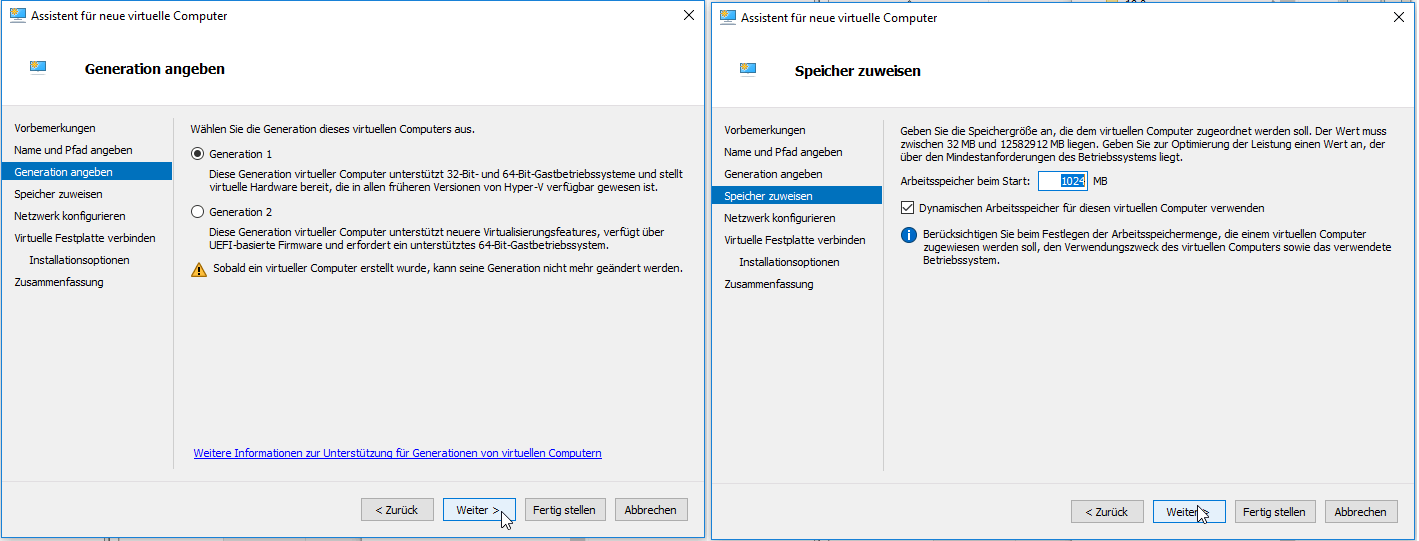
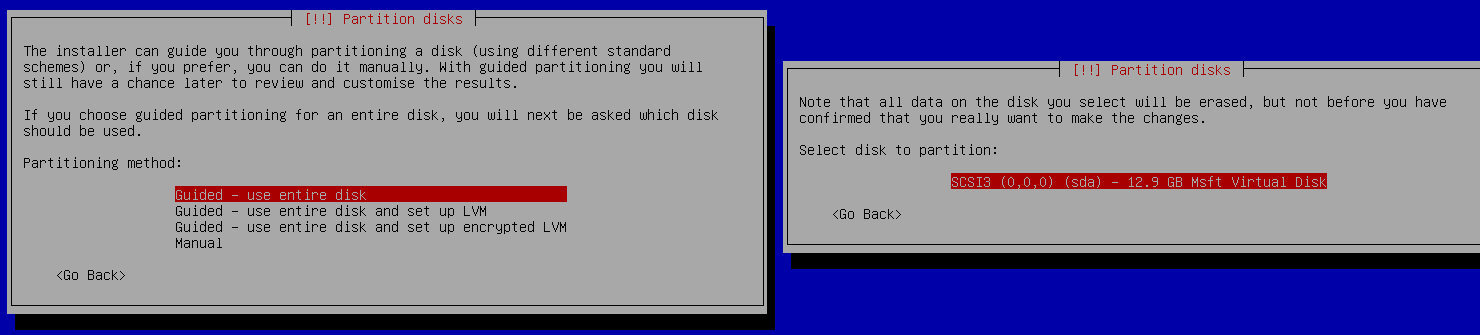
Ein Cronjob ist vergleichbar mit einen Scheduled Task (Geplante Task) in der Windows-Welt. Ausgeführt werden die Jobs über die sogenannte Crontab, einer Liste, die hauptsächlich die Zeitsteuerung und den ausführenden Befehl für den Job enthält.
Crontab einrichten, Cronjob anpassen
Ein Cronjob wird in der Crontab angepasst. Um die Liste aufzurufen oder zu ändern, muss ein Shell-Zugriff (zum Beispiel per putty vorliegen. Bearbeitet kann die Cronatb mit jedem Editor von Linux. Ich empfehle den Editor „vi“ und beziehe mich in diesem Artikel auf den Syntax dieses Editors.
Crontab Steuerbefehle
Der Befehl „crontab“ kann vier Parameter haben:
- „crontab –e“: Mit diesem Aufruf wird die Crontab zum Ändern (editieren) aufgerufen. Wenn die Crontab noch nicht vorhanden ist, wird sie automatisch angelegt
- „crontab –l“: Zeigt die Crontab auf dem Bildschirm an („l“ wie „lesend“, keine Eselsbrücke)
- „crontab –r“: Löscht die Crontab („Remove“)
- „crontab –v“: Zeigt das letzte Änderungsdatum der Crontab an. Dieser Befehl ist nicht auf allen Linux-Systemen vorhanden.
Der Aufbau einer Crontab-Zeile (Cronjob)
Der Aufbau einer Zeile erfolgt nach einem festen Muster. In jeder Zeile steht ein Job. Je nach Editor kann eine Zeile sich über mehrere Zeilen erstrecken (wenn der Aufrufparameter beispielsweise sehr lang ist). Es handelt sich jedoch nur um eine Zeile.
* * * * * Aufruf-des-Skriptes (Befehl) | | | | | | | | | +---- Tag der Ausführung (0 -6, Sonntag = 0) | | | +------ Monat (1-12) | | +-------- Tag (1-31) | +---------- Stunde (0-23) +------------ Minute (0-59)
Wichtige Parameter:
„*“ Der Stern steht für IMMER. Steht ein Stern im Feld „Monat“, wird der Job auf jeden Fall jeden Monat ausgeführt. Steht er im Feld Tag, wird der Job jeden Tag ausgeführt
„/“: Wiederholung: „/2“ im Feld Minute steht beispielsweise für „alle zwei Minuten“, „/5“ im Feld Stunde steht für „alle fünf Stunden“
Crontab Beispiele
Einen Cronjob jeden Tag zu einer bestimmten Uhrzeit ausführen
# Job wird jeden Tag um 23:30 Uhr ausgeführt
30 23 * * * /user/skript-pfad/skript.shCronjob zu einer bestimmten Uhrzeit zum 1. eines bestimmten Monats ausführen
# Job wird jeden 1. im Januar, April,Juni und September um 0:30 Uhr ausgeführt
30 0 1 1,4,6,9 * * /user/skript-pfad/skript.shEinen Cronjob an einem bestimmten Tag ausführen
# Job wird jeden 10. eines Monats um 0:20 Uhr ausgeführt
20 0 10 * * /user/skript-pfad/skript.shEinen Cronjob im Intervall ausführen
# Job wird an jedem Sonntag um 0:30, 2:30, 4:30 (…) ausgeführt
30 /2 * * 0 /user/skript-pfad/skript.shEinen Cronjob jede Minute ausführen
# /1=minütlich, /5=alle fünf Minuten – wenn an erster Stelle
/1 * * * * /user/skript-pfad/skript.shCronjob am ersten Werktag eines Monats ausführen
Leider kenne ich keine einzeilige Lösung für dieses Problem. Mit zwei Zeilen in der Crontab ist dies jedoch durchaus machbar.
0 8 1 * 1-5 /pfad/script.sh
0 8 2,3 * 1 /pfad/script.shWas machen wir hier? In der ersten Zeile starten wir um 8:00 Uhr („0 8“ ) jeden 1. eines Monats („1“) in jedem Monat („*“) das Skript, aber NUR Montag bis Freitag („1-5“). Diese Zeile trifft also zu, wenn der Monatserste auf einen Werktag trifft.
Fällt der Monatserste jedoch auf einen Samstag oder Sonntag, wird hierfür die zweite Zeile benötigt. Diese trifft zu, wenn der der 2. oder 3. eines Monats auf einen Montag fällt.
Gibt es eine bessere Lösung? Schreibt diese gerne in die Kommentare!
Crontab – die Zusammenfassung
Wie hoffentlich zu erkennen ist, kann diese anfangs doch sehr ungewohnte und erst einmal umständlich wirkende Schreibweise alle wünschenswerte Szenarien abdecken. Der Aufbau ist sehr flexibel und lässt keine Wünsche offen. Er bedarf jedoch einiger Übung. Ein Tippfehler oder gar ein „*“ an erster Stelle (=Minute) kann eventuell zu sehr unerwünschten Ergebnissen führen. Daher der Praxistipp, einen neuen Zeitplan erst einmal mit „harmlosen“ Jobs auszuprobieren (Administrator-Mail senden etc).
Cronjob Email
Je nach Einstellung verschickt das Betriebsystem nach jeder Ausführung eines Cronjobs eine automatische Mail. Wie Sie diese deaktivieren können, erfahren Sie im Artikel „Cronjob: Email abschalten„